Discuție Wikipedia:Diacritice
Problema: S cu virgulă sau cu sedilă
modificareÎn limba română literele ş etc. sunt scrise cu virgulă.
De ce se folosesc în Wikipedia variantele cu sedillă?
In romanian the letters ş,ţ etc. are written with a comma below. Why do you use the variant with a cedilla?
Sistemul Unicode conţine următoarele coduri:
Excerpts from the Unicode-Standard:
- Additions for Romanian [Latin Extended-B]
- Ș = Ș (S cu virgulă) latin capital letter s with comma below
- ș = ș (s cu virgulă) latin small letter s with comma below
- Ț = Ț (T cu virgulă) latin capital letter t with comma below
- ț = ț (t cu virgulă) latin small letter t with comma below
- Variantele cu cedillă [Latin Extended-A] variants with cedilla
- Ş = Ş (S cu sedilă) latin capital letter s with cedilla
- ş = ş (s cu sedilă) latin small letter s with cedilla
- Ţ = Ţ (T cu sedilă) latin capital letter t with cedilla
- ţ = ţ (t cu sedilă) latin small letter t with cedilla
- Comentarii privind aceste litere din tabelele Unicode Standard (Comments refering to these letters):
- Turkish, Azerbaijani, Romanian, ...
- this character is used in both Turkish and Romanian data
- a glyph variant with comma below is preferred for Romanian (varianta cu virgulă e preferată în Română)
Cauza
modificarehttp://www.secarica.ro/html/s-uri_si_t-uri.html
- Microsoft defaults. :) Dacă încerci să folosești un keymap care să producă diacriticele pe care le enumeri mai sus în Windows într-o aplicație care nu "știe" de Unicode, ci încerci să salvezi ca ISO-8859-2 de pildă, sunt convins că vor rezulta niște bălării (deși sincer n-am încercat). În plus, și dacă unii dintre utilizatori ar folosi variantele corecte, poți fi sigur că alții vor folosi în continuare default-ul din sistemul lor de operare. Personal prefer să știu că toate diacriticele sunt peste tot la fel, pentru operații automate. Măcar să scrie toată lumea articole cu diacritice, oricum ar fi ele!
- Pot să-ți spun însă altceva. Dacă asta te împiedică să contribui (nu știu cine ești), atunci nu-ți face probleme, este o problemă foarte simplu de rezolvat în viitor -- un simplu search and replace în database rezolvă oricând această problemă, presupunând că la un moment dat s-ar schimba standardul peste tot. --Gutza 11 Dec 2003 09:10 (UTC)
- P.S. După ce ți-am răspuns am citit de curiozitate și textul din pagina la care faci legătură mai sus. Practic văd că tipul care a scris pagina aia spune în esență cam tot ce ți-am spus și eu aici, doar că mai pe larg. De vreme ce chiar tu ai adăugat legătura respectivă, înseamnă că deja știai ce ți-am răspuns mai sus. Drept care probabil că urmăreai alt răspuns, sau vroiai să ridici altă problemă.... --Gutza 11 Dec 2003 09:23 (UTC)
Scuză-mă, nu ştiu să scriu bine pe româneşte (si ca nu folosesc diacritice - n-am tastatura romana si ar trebui sa scriu toate diacriticile în cod numeric HTML). Problema cu diacritice s-a afisat când am cautat un cuvânt cu diacritice. Ne-având tastatura româna am tiparit codul unicode pentru diacritice - si n-am gasit articolul. Când am privit "source code"-ul de la pagina HTML, am observat, ca diacriticele sunt scrise cu alte coduri. Din aceasta cauza am ridicat discutia. Am mai cautat cu Google prin Internet pagini relevante si am citit si pe pagina www.unicode.org unde am gasit legatura (link) de mai sus. Ai dreptate, dupa ce m-am informat, întrebarea initiala a devenit retorica. Considerând faptul, ca in prezent e foarte dificil de a scrie cu diacriticele corecte, cred si eu ca e mai bine sa se foloseasca diacriticile false, decât sa se scrie fara diacritice.
Reason for the misspelling of these characters: Microsoft defaults :) The Microsoft Standard uses the false character encoding, false keyboard layout and most of their fonts don't contain the glyphs for the right Romanian characters.
Cum se manifestă problema?
modificareTotusi mai ramân niste probleme mai mici:
- Referintele (link) de la Wikipediile internationale la Wikipedia româna trebuie scrise cu diacriticele false.
- aceste referinte trebuie schimbate, când în Wikipedia româna diacriticile sunt corectate. Schimbul nu se poate efectua cu "search & replace", e probabil sa mai existe si referinte la alte limbi (turcesc ?) cu diacriticele cu sedila.
- mai exista si alte "operating systems"(Sisteme de operare) ca Windows, care folosesc standardul Unicode.
Sper ca nu m-am exprimat prea gresit. Multumesc pentru raspuns - nu cred ca a fost inutil, poate mai sunt si altii care se lovesc de problema diacriticelor false. Stiu prea putina româna pentru a contribui la Wikipedia româna, dar înteleg destul ca sa fac eventual legaturi cu paginile române în Wikipedia german sau engleza
What might be the problem by using false character codes?
- it violates the Unicode-standard
- there might be compatibility problems with other OS (Linux)
- there might be problems when you refer from the international Wikipedia to Romanian articles
Propuneri pentru rezolvarea/ameliorarea problemei
modificare- Nu-ți face griji, se înțelege foarte ușor ce spui, chiar dacă se vede că nu ești vorbitor nativ de română (cred că vorbesc în numele oricărui român care citește asta, cu atât mai mult e de apreciat că faci efortul să scrii în română; dacă ți-e deosebit de peste mână, putem continua în engleză, nu e nici o problemă). Da, ridici o problemă interesantă, într-adevăr asta poate deveni supărător pe termen lung. Nu știu ce soluție să sugerez... Ce pot face eu personal este să modific layout-ul de tastatură pe care îl ofer în josul paginii Wikipedia:limba română conține diacritice -- însă nu știu cât de multă lume îl folosește. Mai mult nu pot face: nu pot obliga utilizatorii Wikipedia să folosească HTML entities (ar și fi stupid), și nici să folosească layout-ul meu.
- Alte două soluții posibile:
- S-o lăsăm așa pe termen mediu, iar atunci când se va împământeni standardul corect să scriu un script în PHP care să facă modificările de rigoare pe toate Wikipediile, numai la link-urile către Wikipedia în română (nu ar fi un efort considerabil nici pentru mine, nici pentru database);
- Să-i propunem lui Brion sau altcuiva să accepte un patch la Wikipedia în română, patch care să înlocuiască diacriticele "proaste" cu diacritice "bune" de fiecare dată când se editează un articol.
- Tu ce părere ai? --Gutza 11 Dec 2003 16:18 (UTC)
Nici eu nu stiu care ar fi solutia optima. Pe lânga problema editarii diacriticelor se pune si problema afisarii (display) literelor.
- Mai multe fonturi (fonts) au numai simboluri pentru litererle cu sedila. Sansa de a fi afisat corect e mai mare daca folosesti varianta cu sedila. (Unele programe înlocuiesc simboluri care lipsesc din fontul actual cu simboluri din alt font, textul nu apare gaurit, dar cum-va deranjat).
- Pentru utilizatorii internationali, nu face diferenta la editare daca folosesc sedila sau virgula - unii vor prefera standardul unicode, altii vor prefera sedila, fie ca arata mai bine pe ecran, fie ca s-au luat dupa o pagina de internet româna.
- Nu cunosc sistemul Windows român, nu stiu daca diacriticele "bune" sunt afisate in mod corect. Dupa ce am citit pana acum, am impresia ca pentru majoritatea utilizatorilor editarea literelor cu sedila e cu mult mai usor.
Propunerea mea este (daca e posibil din punct de vedere technic):
- pentru fiecare articol cu diacritice cu sedila sa existe un #redirect cu titlul scris cu diacriticele bune.
- cautarea sa fie adaptata, ca sa nu deosebeasca între cele doua variante
- utilizatorii pot folosi la editare ambele variante
- textele sa fie salvate numai într-o singura varianta (actual as prefera sedila), codurile HTML sa fie transformate în Unicode
- Nu chiar asa important: oaspetii (visitors) Wikipedei au posibilitatea de a alege, daca paginile sunt trimise cu diacritic bune sau proaste (n-ar fi prea complicat cu cookies+php)
- întroducerea unui tag <uc> sau <unicode> sau ... pentru a masca literele care sunt scrise intentional cu sedila (cuvinte turcesti ...).
Proposals (traducerea engleză)
modificareFor anyone who may be half following this as a technical linking issue and does not have too much Romanian, I'm going to try to translate the preceding proposal. Gutza or anyone else, please feel free to correct me if I misunderstood something. I didn't try to follow the whole discussion here, just the upshot; Romanian is relatively slow going for me.
This relates to the fact that Romanians consider (for example) ș = ș (s with comma ) more correct than ş = ş (s with cedilla). If your system is like mine, and like many even in Romania, you can't see (or readily type) the "good" diacriticals. Therefore there are also some good reason to use the "bad" diacriticals. To avoid future problems consider the following
proposal (if possible from a technical point of view):
- for every article with diacritical marks with a cedilla there will be a #redirect with the title written with "good" diacriticals.
- Search will be adapted, so that it doesn't distinguish between these two variants
- users can use both variants while editing
- text will be saved using only a single variant (the current preference is for a cedilla), HTML codes will be transformed into Unicode
- Less important: Wikipedia visitors can choose whether pages are displayed with "good" or "bad" diacriticals (this shouldn't be too complicated to implement with cookies+php)
- introduce a tag <uc> or <unicode> or ... to mark literels that are intentionally written with cedilla (Turkish words ...).
- -- Jmabel (US) 11 Dec 2003 19:28 (UTC)
--Diacrit 11 Dec 2003 20:12 (UTC)
Test cu diferite fonturi
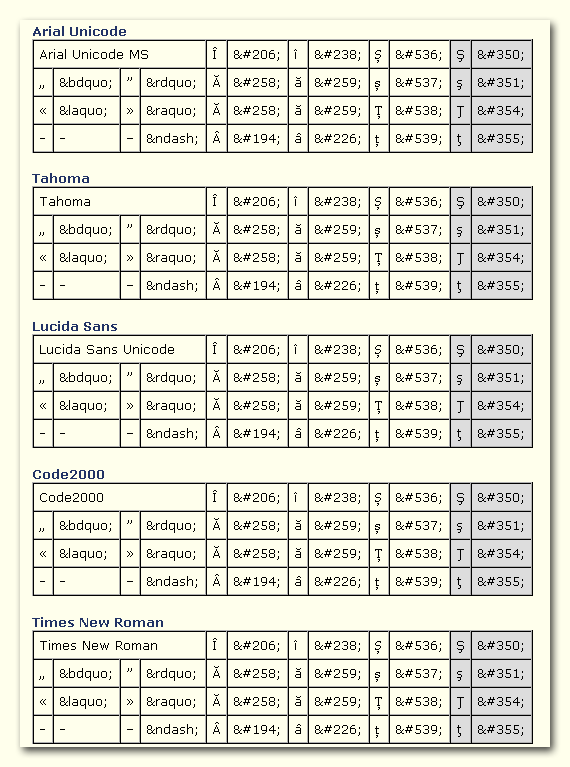
modificareTest cu diacriticele şi ghilimelele româneşti (ultima coloana: cedilă). Diacriticele sunt scrise în cod numeric HTML şi în Unicode (în paranteze). Test for Romanian characters in different fonts (last column contains the glyphs with cedille). Glyphs are encoded as decimal HTML entities and in Unicode.
Arial Unicode
modificare| Arial Unicode MS | Î (Î) | Î | î (î) | î | Ș (Ș) | Ș | Ş (Ş) | Ş | |||
| „ („) | „ | ” (”) | ” | Ă (Ă) | Ă | ă (ă) | ă | ș (ș) | ș | ş (ş) | ş |
| « («) | « | » (») | » | Ă (Ă) | Ă | ă (ă) | ă | Ț (Ț) | Ț | Ţ (Ţ) | Ţ |
| - | - | – (–) | – | Â (Â) | Â | â (â) | â | ț (ț) | ț | ţ (ţ) | ţ |
Tahoma
modificare| Arial Unicode MS | Î (Î) | Î | î (î) | î | Ș (Ș) | Ș | Ş (Ş) | Ş | |||
| „ („) | „ | ” (”) | ” | Ă (Ă) | Ă | ă (ă) | ă | ș (ș) | ș | ş (ş) | ş |
| « («) | « | » (») | » | Ă (Ă) | Ă | ă (ă) | ă | Ț (Ț) | Ț | Ţ (Ţ) | Ţ |
| - | - | – (–) | – | Â (Â) | Â | â (â) | â | ț (ț) | ț | ţ (ţ) | ţ |
Lucida Sans
modificare| Arial Unicode MS | Î (Î) | Î | î (î) | î | Ș (Ș) | Ș | Ş (Ş) | Ş | |||
| „ („) | „ | ” (”) | ” | Ă (Ă) | Ă | ă (ă) | ă | ș (ș) | ș | ş (ş) | ş |
| « («) | « | » (») | » | Ă (Ă) | Ă | ă (ă) | ă | Ț (Ț) | Ț | Ţ (Ţ) | Ţ |
| - | - | – (–) | – | Â (Â) | Â | â (â) | â | ț (ț) | ț | ţ (ţ) | ţ |
Code2000
modificare| Arial Unicode MS | Î (Î) | Î | î (î) | î | Ș (Ș) | Ș | Ş (Ş) | Ş | |||
| „ („) | „ | ” (”) | ” | Ă (Ă) | Ă | ă (ă) | ă | ș (ș) | ș | ş (ş) | ş |
| « («) | « | » (») | » | Ă (Ă) | Ă | ă (ă) | ă | Ț (Ț) | Ț | Ţ (Ţ) | Ţ |
| - | - | – (–) | – | Â (Â) | Â | â (â) | â | ț (ț) | ț | ţ (ţ) | ţ |
Times New Roman
modificare| Arial Unicode MS | Î (Î) | Î | î (î) | î | Ș (Ș) | Ș | Ş (Ș) | Ş | |||
| „ („) | „ | ” (”) | ” | Ă (Ă) | Ă | ă (ă) | ă | ș (ș) | ș | ş (ș) | ş |
| « («) | « | » (») | » | Ă (Ă) | Ă | ă (ă) | ă | Ț (Ț) | Ț | Ţ (Ț) | Ţ |
| - | - | – (–) | – | Â (Â) | Â | â (â) | â | ț (ț) | ț | ţ (ț) | ţ |
--Diacrit 11 Dec 2003 21:36 (UTC)
Interestingly, I see the Tahoma correctly, but the other S/s-with-comma (virgulă) & T/t-with-comma are lost to me. Could others chime in to say if that's typical? -- Jmabel (US) 11 Dec 2003 23:19 (UTC)
- That's curious, I don't see any difference between those fonts. Here:
- Gutza 12 Dec 2003 10:13 (UTC)

Do you have some of the fonts above installed? Maybe font selection doesn't work proper in your browser or document specific fonts are overridden by user fonts?--Diacrit 12 Dec 2003 10:20 (UTC)
- Me again. Found out why, worth noting: I was using Cologne Blue, apparenty that overrides all font settings in the page. I can see everything properly in Mozilla, but in IE I get exactly the same behaviour as Jmabel.
- I added the actual characters in Unicode in the source between brackets out of curiosity -- looks like no difference whatsoever, at least that's consistent. --Gutza 12 Dec 2003 10:35 (UTC)
- And again myself. :) It does work properly in Mozilla, but that's because Mozilla substitutes the missing glyphs, as per Diacrit's comment below. The curious thing is that Mozilla seems to render Tahoma properly, and everything else using Times New Roman (obviously talking only about t/s with comma, the rest are shown properly everywhere). IE however doesn't display the proper glyphs for Times New Roman! Which makes me conclude the support for those characters is rather inconsistent across fonts/browsers for the time being... --Gutza 12 Dec 2003 10:47 (UTC)
Fonturi (TTF) cu diacritice româneşti (cu virgulă)
modificareFonts containing glyphs for displaying s, t with comma
WebBrowser care suportă Unicode
modificareBrowsers supsorting Unicode
- suport complet pentru diacritice și utf-8
- Safari 3 (beta la această dată - 30 august 2007 18:02 (EEST))
- arată numai glifurile conţinute în fontul specificat (displaying only glyphs contained in the used font)
- Internet Explorer 5.5
- înlocuieşte glifurile care lipsesc cu glifuri din alte fonturi (substitutes missing glyphs with glyphs from other fonts)
- Opera 7.x
- Mozilla 1.x
--Diacrit 12 Dec 2003 10:04 (UTC)
Propunere pentru editare
modificare(am împartit pagina în mai multe capitole ca sa fie mai bine editabila)
Oare ar fi posibil ca la paginile de editare sa fie adaugate niste butoane cu care se pot inserta (cu javascript) si diacritice (vezi exemplul) ?
Is it possible to add some buttons to the "edit"-pages in order to insert via javascript some special characters (similar to the example below)?
<form action="">
<textarea id="tf"></textarea>
<input type="button" value="Ş" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'Ş';">
<input type="button" value="ş" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'ş';">
<input type="button" value="Ţ" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'Ţ';">
<input type="button" value="ţ" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'ţ';">
<input type="button" value="Ș" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'Ș';">
<input type="button" value="ș" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'ș';">
<input type="button" value="Ț" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'Ț';">
<input type="button" value="ț" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'ț';">
<input type="button" value="Ă" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'Ă';">
<input type="button" value="ă" onClick="javascript:document.getElementById('tf').value=document.getElementById('tf').value+'ă';">
</form>
--Diacrit 12 Dec 2003 13:13 (UTC)
Yes, but:
- This will require specific changes to the Romanian Wikipedia, I'm not sure how well this is regarded by Wikimedia;
- The effort to write using those would be considerable; for any OS, the keyboard layouts are free, so I think there would be less effort to install the Romanian locale than use those buttons even if you only write one single article. Plus that way you become more proficient using the Romanian keyboard, so editing or writing subsequent articles would that much faster, whereas using the on-screen buttons will never be fast;
- Even if both arguments above are somehow proved to be wrong, we still have the problem of cedilla vs. comma, see my comments below the tables. IMHO that's what we should first focus on deciding.
--Gutza 12 Dec 2003 13:45 (UTC)
- These are good arguments. Maybe there could be offerd an additional edit page, because there might be some users, who are willing to write some shorter articles or comments, but are not able to install the Romanian keyboard (because they are no admins, using some special OS, aren't experienced enough). If they don't know the numerical code of diacrits, they won't be able to write them. Due to this problem there should at least be included a line with all special characters (and html codes) so that you can isert them by copy and paste (or enter html entities). --Diacrit 12 Dec 2003 14:27 (UTC)
- Count me as one of those who won't go around installing different keyboard mappings. I regularly work in at least four languages. Ever compare (for example) and English and a German keyboard? Letters that are in both languages are in different places. I want to touch-type, at least much of the time. I cannot do this if I am constantly changing keyboard layout. -- Jmabel (US) 13 Dec 2003 00:29 (UTC)
Well, this can really be done with a simple frameset hosted on any server anywhere. I'll see if I have time this weekend to write the HTML and place it on my server. --Gutza 12 Dec 2003 15:10 (UTC)
- Refering to the problem of cedilla vs. comma, I've written my suggestions above. To avoid display problems I'd prefere, that at least the HTML pages should be delivered with the cedilla version - the comma version should be used only at user request (if possible). The internal storage format in the database should be the comma version, if it doesn't complicate things too much. --Diacrit 12 Dec 2003 14:27 (UTC)
It does. Big time. The servers are already overloaded, not only with requests but CPU-wise as well. Also, since this would already require some automated procedure, that can wait until (a) comma diacriticals go mainstream or (b) the Wikimedia servers receive the CPU boost they deserve. All in all, as a Romanian I don't find this to be such a major inconvenient (cedillas instead of commas). While technically comma is what should be used, and I completely agree with that, the difference is so small that I literally have to squint to notice it... --Gutza 12 Dec 2003 15:10 (UTC)
You are right, that this isn't a major inconvenence with one exception: there remains my initial problem with the search. If it is too complicated to alter the search function, there still remains the possibility to create for every article an redirect when it's title contains ş and ţ. --Diacrit 12 Dec 2003 15:40 (UTC)
There should also be some support for entering diacrits into the search field, you could insert (on the main page) the sentence:
- Pentru cautare puteti sa utilizati diacriticele urmatoare si cu cut and paste: ÂâÎÎş...
of course in correct Romanian :-)
By the way, this would be also a good idea for other international Wikipedias. For example in German there are the Umlauts äöü. If you're searching "Hören" and enter "Horen" you'll get something different than you wanted. If you don't have a german keyboard and don't know the ASCII code, the only possibility is to use cut and paste. I'll make a suggestion ... --Diacrit 12 Dec 2003 16:01 (UTC)
Take a look at the Spanish language wikipedia (http://es.wiki.x.io) does when you go to edit an article. Right below the edit box are all the letters with diacriticals so you can cut and paste. -- Jmabel (US) 13 Dec 2003 00:29 (UTC)
Edicode - pagină externă pentru editarea diacriticelor în Unicode
modificareIf you have to insert diacriticals for different languages - here is an external page Edicode where you can enter the characters by pressing some buttons. I've made heavily use of Javascript and DOM , therefore in older browser it may not work. (It works with IE 6, Moz.1.5 Opera 7). There are some button panels for Latin-1 Supplement, Latin Extended-A & B and two small button sets for Romanian diacriticals and German umlauts. It's not designed to write whole articles, but if you have only some words with diacriticals (even in different languages) it will be quite practical (I hope :-) --Diacrit 13 Dec 2003 11:01 (UTC)
Some Wikipedias still don't use Unicode/utf-8. Therefore you have to enter all Unicode characters, that are not in the specific codepage, as numerical HTML entities. If you have problems with texts written with Edicode, try Enticode, the version with entities (numeric character references). Here's a mix of special characters from different languages, produced with Edicode: Ölmühle Fuß Țară Øre Ångström © ‚ȝ‘–yogh ȘșȚțȘșȚț Fűller Français --Diacrit 13 Dec 2003 11:41 (UTC)
Linkul nu mai funcționează. am găsit programul aici Edicode Ark 9 iulie 2008 08:33 (EEST)
Opinie referitoare la diacritice
modificareUn motiv pentru care nu le folosesc pe internet este ca afecteaza indexarea in motoarele de cautare. Atata vreme cat probabil ca 95 din 100 de cautari sunt fara diacritice, daca eu folosesc diacritice pe site inseamna ca pierd acesti potentiali vizitatori (pentru ca motoarele de cautare vor cauta exact textul introdus = nu vor sti ca pamant si pământ sunt acelasi cuvant).
- Din păcate aceasta nu este adevărat (și s-a mai adus acest argument și cu alte ocazii): o simplă căutare pe Google după cele două grafii ale cuvântului "pământ", cu, respectiv fără diacritice, ne arată același număr de rezultate. --Vlad|-> 23 noiembrie 2005 15:08 (UTC)
Problema este ordinea afișării rezultatelor, nu numărul lor. Încercați să căutați "instalatii" și primul rezultat va fi Facultatea de Instalații. Încercați "instalații" și pagina va fi undeva în jurul locului 30. --Alexandru, 89.136.157.137 (discuție) 20 ianuarie 2009 20:56 (EET)
Tastatură
modificareCred că pagina asta ar trebui să conțină o secțiune tehnică în care să se explice, pentru diferite sisteme de operare, cum se instalează tastatura românească. 99% din pagină este o pledoarie pentru scrierea cu diacritice, cu care sînt total de acord, dar numai ultima frază e o mică încercare de a spune cum se face asta. Să nu uităm că avem mulți contribuitori care nu sînt deloc pricepuți la chestii tehnice. Să-i ajutăm. --AdiJapan 23 noiembrie 2005 15:53 (UTC)
Character Encoding
modificareSubscriu si eu aici. De exemplu acum folosesc Mozilla Firefox 1.5.0.2 sub Linux/Gnome si am probleme la vizualizarea tuturor paginilor din internet: sunt afisate doar diacritice pt Â(Â)  â(â) âÎ(Î) Î î(î) îȘ(Ș) Şș(ș) ş nu sunt afisate:Ă (Ă) Ă ă(ă) ă Ț(Ț) ȚȚ(Ț) Ţț(ț) țț(ț) ţ ele fiind inlocuite cu niste "patratele". In meniu firefox, la "character encoding" e selectat Unicode (UTF-8). Am incercat si cu Romanian (ISO-8859-16) sau Romanian (MacRomanian) sau Central European(ISO-8859-2) paginile aratand mai rau decat cu Unicode UTF-8. Am incercat apoi toate la "character encoding" dar paginile devin complet ilizibile. Mentionez ca nu gasesc in setarile firefox fonturile enumerate de voi mai sus care ar contine diacritice, deci instalez fonturile lipsa si rezolv problema? Oricum, ridic 2 intrebari: 1. care este caracterul sau codul specific limbii romane? sau asta depinde de fontul folosit (daca acesta stie sau nu diacritice) si 2. cum pot sa citesc si eu fara probleme o pagina de internet in Firefox, pe Linux :( nu neaparat cu diacritice! ca sa nu mai fac slalom printre patratele amestecate cu cuvinte. Acesta nu este un apel pt un tutorial de configurare (exista pagini dedicate pt asta). <Mihai 23.05.2006>
- Eu folosesc Internet Explorer și nu am nici un fel de probleme, de la început a mers normal. N-am experiență cu Firefox, deci nu vă pot ajuta.
- Din cîte știu paginile de la Wikipedia sînt toate codate în Unicode, care suportă o mulțime de limbi cu sisteme de scriere din cele mai ciudate. Afișarea la Wikipedia în română (ca și multe alte proiecte scrise în alfabet latin) se face cu fontul Arial, care conține și diacriticele românești.
- Deci problema trebuie să fie de compatibilitate între browserul dumneavoastră și HTML-ul generat de Wikipedia. Sincer, sînt de destulă vreme pe aici dar n-am mai auzit pe nimeni plîngîndu-se de probleme similare. Sper să găsiți buba... — AdiJapan ☎ 24 mai 2006 15:12 (EEST)
- Soluția pentru problema lui Mihai: Am avut și eu problema ta, dar cumva a dispărut când am actualizat sistemul meu. Oricum, trebuie să schimbi font-ul implicit pe FireFox (Editare|Preferințe|Conținut/Font implicit) sau în programul respectiv. La mine merge bine Tahoma, Arial sau, bănuiesc, FreeSans trebuie să meargă.
- Filip --141.85.0.66 23 iulie 2006 19:19 (EEST)
Windows Vista
modificareVista include suport pentru caracterele cu virgulă, deci în viitor ar trebui ca peste 90% :-D din calculatoare să poată afișa corect diacriticele. Vezi și link-ul de mai jos, un update pentru XP pentru font-uri: http://www.microsoft.com/downloads/details.aspx?FamilyID=0ec6f335-c3de-44c5-a13d-a1e7cea5ddea&DisplayLang=en
Ghilimele
modificare„Ghilimelele“ corecte în limba română nu sunt cele cu 99 în jos și 66 în sus? ← Acest comentariu nesemnat a fost adăugat de 79.112.27.72 (discuție • contribuții).
- Eu așa am învățat la școală, dar se pare că ori s-au schimbat lucrurile ori am învățat eu greșit -- în toate sursele curente pe care le-am consultat se indică 99 pentru ambele. Vedeți și aici: en:Romanian_language#Punctuation_and_capitalization. --Gutza DD+ 4 mai 2008 17:42 (EEST)
- De vină sînt nu Academia, nici tipografii, ci... programatorii. --Feri Goslar 4 mai 2008 18:15 (EEST)
- De ce spuneți asta? Știți istoria acestei povești? (E o întrebare complet candidă.) --Gutza DD+ 4 mai 2008 19:28 (EEST)
- Tipografia profesionistă continuă să culeagă «99_66». «P-afară», alandala (preponderent englezește «66_99»). (Remarc și pe calculatoarele mele în Word, sub XP și Vista: îmi scrie cînd 99_66, cînd 66_99, cînd <<_>>, adică «_». În același text.) -- Feri Goslar
Tabel Diacritice și semne de punctuație românești
modificare| Caracter | {{unicode|}} | Cod Unicode | Cod UTF-8 | Cod HTML1 | Cod HTML2 | Cod HTML3 | Cod Ext ASCII - en:ISO 8859-2 (Keyboard Code) | Cod Ext ASCII - en:Code page 437 (Keyboard Code) |
|---|---|---|---|---|---|---|---|---|
| î | î | U00EE | C3AE | î | î | î | 238 (Alt + 0238) | 140 (Alt + 140) |
| Î | Î | U00CE | C38E | Î | Î | Î | 206 (Alt + 0206) | - |
| â | â | U00E2 | C3A2 | â | â | â | 226 (Alt + 0226) | 131 (Alt + 131) |
| Â | Â | U00C2 | C382 | Â | Â | Â | 194 (Alt + 0194) | - |
| ă | ă | U0103 | C483 | ă | ă | - | 227 (Alt + 0227) | - |
| Ă | Ă | U0102 | C482 | Ă | Ă | - | 195 (Alt + 0195) | - |
| ș (cu virgulă) | ș | U0219 | C899 | ș | ș | - | - | - |
| Ș (cu virgulă) | Ș | U0218 | C898 | Ș | Ș | - | - | - |
| ț (cu virgulă) | ț | U021B | C89B | ț | ț | - | - | - |
| Ț (cu virgulă) | Ț | U021A | C89A | Ț | Ț | - | - | - |
| - | - | - | - | - | - | - | - | - |
| ş (cu sedilă) | ş | U015F | C59F | ş | ş | - | 186 (Alt + 0186) | - |
| Ş (cu sedilă) | Ş | U015E | C59E | Ş | Ş | - | 170 (Alt + 0170) | - |
| ţ (cu sedilă) | ţ | U0163 | C5A3 | ţ | ţ | - | 254 (Alt + 0254) | - |
| Ţ (cu sedilă) | Ţ | U0162 | C5A2 | Ţ | Ţ | - | 222 (Alt + 0222) | - |
| - | - | - | - | - | - | - | - | - |
| « | « | U00AB | C2AB | « | « | « | 171 (Alt + 0171) | 174 (Alt + 174) |
| » | » | U00BB | C2BB | » | » | » | 187 (Alt + 0187) | 175 (Alt + 175) |
| „ | „ | U201E | E2809E | „ | „ | „ | 132 (Alt + 0132) | - |
| ” | ” | U201D | E2809D | ” | ” | ” | 148 (Alt + 0148) | - |
| – | – | U2013 | E28093 | – | – | – | 150 (Alt + 0150) | - |
{*} - Windows-1252 - variantă a en:Extended ASCII și en:ISO 8859-2
Bibliografie
Observații
- În OpenOffice funcționează șț și cu virgulă și cu sedilă, cu toate fonturile.
- O soluție foarte bună mi se pare folosirea utilitarului AutoHotkey, care este foarte folositor pentru cei care nu doresc să instaleze layout-ul de tastatură în limba română sau nu au posibilitatea (unele persoane folosesc același calculator cu altele pe care le încurcă instalarea acestui layout). Astfel, prin linia următoare: "!^s:: PutUni("C899")", la apăsarea combinației CTRL+ALT+s - se obține ș cu virgulă. Linia "<^>!s:: PutUni("c59f")" face ca prin apăsarea combinației CTRL+Alt Gr+s - se obține ș cu sedilă. Pentru mine unul soluția este de departe cea mai bună pentru că direct am acces la layout-ul englez (care il am deja în sânge), iar la diacritice am acces simplu de asemenea, fără să mai schimb layout-ul. Plus că mi-am setat programul să am acces la ambele variante de ș și ț - cu virgulă și cu sedilă.
- Cel mai simplu mod de aflare a codului UTF-8 a unui caracter, este copierea lui într-un editor de gen Notepad2, se alege opțiunea de encodare a fișierului pe UTF-8, se introduce caracterul, se salvează fișierul, care apoi poate fi vizualizat cu un viewer cum ar fi cel din Total Commander, care are opțiunea de vizualizare în format Hexa. Codul hexa afișat acolo este exact codul UTF-8. La fel și pentru codul Unicode, doar că se selectează opțiunea "Unicode Big Endian".
- Articolele Ș și Ț sunt scrise cu ș și ț cu sedilă (șț), și chiar numele articolelor sunt scrise cu sedilă. Propun schimbarea cu virgulă, dacă nu sunt probleme cu afișarea în vreun browser sau sistem de operare.
Întrebări
- Care este istoria caracterelor speciale («»„”–), când și cum au apărut ele în limba română?
- Dacă bine îmi amintesc, la școală am învățat că ghilimelele se scriu cu „ (99 jos) și “ (66 sus), nu cu „ (99 jos) și ” (99 sus) dar poate mă înșel. Care este poziția academiei române?
- De ce arată atât de diferit Ț de {{unicode|Ț}} (același caracter)?? Dacă nu scrii cu {{unicode|Ț}}, Ț-ul cu sedilă apare ca un Ț cu virgulă! (Folosesc Mozilla Firefox în Windows XP)
- câte alte variante de diacrititce există? Am găsit caracterele îÎâ și la codurile Unicode U00EE, U00CE, U00E2, U00C2 - vezi aici unicode.coeurlumiere.com mai există și altele?
- La Discuție Wikipedia:Diacritice#Fonturi (TTF) cu diacritice românești (cu virgulă) sunt recomandate fonturile Lucida Bright și Lucida Typewriter (monospace), dar nu le găsesc în Windows XP-ul meu. Unde se întâlnesc aceste fonturi? În Adobe Acrobat? sau în Linux?
- Apropo de Linux, care este situația acolo cu șț cu virgulă și sedilă?
Ark 10 iulie 2008 06:55 (EEST)
- Răspuns la 2: ghilimelele corecte sînt cele de forma 99 jos 99 sus. Vezi: Academia Română, Institutul de Lingvistică „Iorgu Iordan”, Îndreptar ortografic, ortoepic și de punctuație, ediția a V-a, Univers Enciclopedic, București, 1995. (Detalii și online la http://www.acad.ro/, dreapta-jos.)
- La 3: Format:Unicode forțează browserul să aleagă dintr-un anumit set de fonturi, care conțin mai multe caractere Unicode decît fonturile normale. De-asta arată altfel. Partea cu asemănarea dintre T-sedilă și T-virgulă este explicată în articolul Ț. Aceeași asemănare ar fi apărut și la Ș dacă litera nu era folosită și în limba turcă, unde normală este forma cu sedilă.
- La 4: fiecare caracter Unicode are nu doar o formă grafică, ci și un rost bine precizat, de exemplu pe î îl cheamă „I minuscul cu circumflex”. Deci chiar dacă două litere seamănă între ele nu înseamnă că sînt identice. Dar în cazul literelor îÎâÂ, cele pe care le-ai găsit (U00EE, U00CE, U00E2, U00C2) sînt singurele care există; nu le-ai găsit „și la codurile”, ci doar la acele coduri.
- La 1: nu este locul aici pentru o asemenea discuție. La 5 și 6: nu știu. — AdiJapan 10 iulie 2008 07:00 (EEST)
Mersi de răspunsuri. La 4: acum înțeleg. Vezi aici, unicode.coeurlumiere.com de exemplu: Linia 00C0 - coloana E (adică cod U00CE), și linia 0200, coloana A (adică cod U020A). Arată cam foarte la fel - adică Î. Așa că cel puțin pare că ar exista două variante, adică oricine poate fi indus în eroare de așa ceva pentru că arată foarte similar. Însă dacă dau search, mi-l găsește doar pe U00CE. Scuze că iar „propun” ceva dar mi se pare că merită menționat în articolul acesta asemănarea, pentru a ajuta cititorul să evite eventuale confuzii. Uite varainta corectă „îÎâ” (U00EE, U00CE, U00E2, U00C2) și cea falsă „ȋȊȃȂ” (U020B, U020A, U0203, U0202). Ark 10 iulie 2008 09:46 (EEST)
| î Î â Â |
| ȋ Ȋ ȃ Ȃ |
- Literele false nu sînt false, ci aparțin altor limbi sau se folosesc în alte situații. În particular U020B, U020A, U0203, U0202 au ca semn diacritic căciula întoarsă, nu circumflexul. Îți recomand să consulți autoritatea în domeniu, adică Unicode. Dar românii nu au la tastatură căciuli întoarse, deci posibilitatea de confuzie e practic nulă. Ar fi inutil să intrăm în asemenea detalii inutile. Experiența m-a învățat că o pagină de explicații cu cît e mai lungă cu atît e mai puțin citită, iar efectul este contrar celui dorit --- se fac mereu și mereu aceleași greșeli elementare.
- Atenție la termeni, pagina Wikipedia:Diacritice nu e articol. Articole sînt numai paginile din spațiul de nume principal, adică acelea care conțin materialul enciclopedic propriu-zis. — AdiJapan 10 iulie 2008 10:13 (EEST)
Fals. Eu unul am făcut deja confuzia, și 1 > 0 deci posibilitatea de confuzie nu este nulă. Poate este mică, sau insignifiabilă. Ești în eroare dacă tu crezi că toți românii au posibilitatea sau vor să își instaleze "layout-ul" (sau cum s-o fi numind) românesc. Unii nu pot din motive obiective. Alții, chiar dacă pot, preferă programe de macrouri și hotkeys pur și simplu pentru că oferă de 10 ori mai multe posibilități și li se pare mai la îndemână lucrul acesta. sau: un român care locuiește în america nu prea găsește de cumpărat tastatură românească și poate că nu va avea chef de lipit ș,ț,î cu scoci pe butoane. Eu unul am făcut confuzia chiar consultând Unicode. Am parcurs cu atenție toată pagina aceasta de discuții. Chiar la început este un link (apropo nu funcționa și l-am corectat eu - așa că poate am fost și primul care l-am consultat), acesta [Latin Extended-B]. Acolo la row A, column 20, găsesc Î-ul "fals". Am făcut o eroare și l-am confundat cu cel corect. Se poate întâmpla și altcuiva așa ceva? cu siguranță. Odată introdus codul greșit în programul de hotkeys, utilizatorul cu pricina începe să umple paginile cu Î-ul greșit până se prinde că a făcut o greșeală. Unde mai pui că la mărimea normală a fontului, este extrem de ușor de confundat cu Î-ul românesc pentru că nu se vede că e rotundă căciula aceea. Dar asta nu înseamnă că părerea mea este cea mai bună când spun că informația cu cele două Î-uri ar fi bine de inclus în pagina principală. E doar o opinie acolo. Părerea mea este că tabelul de mai sus ar prinde bine în pagina principală. Este o părere, nu o lua ca pe o propunere venită de la o persoană care crede că deține adevărul absolut. Umm, îmi scapă acuma, cum îi zice atunci dacă nu articol? Ark 10 iulie 2008 14:02 (EEST)
Ahh, proiect. Ok am reținut diferența. Ark 11 iulie 2008 02:26 (EEST)
SO recente
modificareUtilizatorii de Windows Vista și distribuții recente de Linux tastează implicit cu caracterele ș și ț cu virgulă, ca urmare, când vor căuta pe google sau wikipedia nu vor găsi mai nimic. ← Acest comentariu nesemnat a fost adăugat de Alexxed (discuție • contribuții).
- Google echivalează și S-virgulă și S-sedilă cu S simplu, analog la Ț, Deci găsește articolele din Wikipedia. Problema se pune (încă) doar atunci cînd vizitatorii folosesc funcția noastră de căutare, unde trebuie neapărat scris cu același semn diacritic ca în articol.
- Din păcate soluția pe care o sugerați, aceea de a trece la diacriticele corecte, este deocamdată nepractică: mulți văd încă pătrățele în loc de S-virgulă și T-virgulă, ceea ce e o problemă mult mai gravă decît cea a căutării sau cea estetică. — AdiJapan 14 noiembrie 2008 19:52 (EET)
- În plus, nici în privința căutării problema de fapt nu există: căutare „cașcaval” (cu virgulă) versus căutare „cașcaval” (cu sedilă). --Gutza DD+ 14 noiembrie 2008 20:07 (EET)
Caractere corecte și anunț
modificareDiscuție mutată la Discuție Wikipedia:Corectarea diacriticelor.
Program conversie
modificareNu se poate obliga toată lumea să utilizeze Windows Vista
modificareOricât de bine intenționați ați fi, totuși nu este posibil să se utilizeze diacritice care nu sunt acceptate de claviaturile standard ale programelor Windows, pe care majoritatea utilizatorilor le utilizează. Ceea ce se face este a introduce un sistem pe care îl pot utiliza doar inițiații și care nu este la îndemâna majorității contributorilor la Wikipedia.
Este aberant să se ceară colaboratorilor să utilizeze Windows Vista care, chiar dacă are anumite avantaje cu privire la diacritice, este un sistem care are o multitudine de desavantaje. Personal am încercat Vista și am revenit la XP. Afil (discuție) 8 iulie 2010 04:50 (EEST)
- V-am răspuns la Wikipedia:Cafenea#Diacriticele noi. — AdiJapan 8 iulie 2010 07:12 (EEST)
Diacriticele altor limbi
modificareSe poate face ca, atunci când se caută Agri, motorul de căutare să găsească și pagina Ağrı ? Ar trebui să existe pe undeva un tabel cu similitudini. De exemplu, căutând „Musetel”, primul rezultat care apare este Mușețel. — Ark25 (discuție) 19 august 2010 01:12 (EEST)
- Te încurajez să raportezi un bug în bugzilla:. Cu ocazia asta poate aflăm și noi ce e "ı" (arată ca un i, dar se pronunță ca u, vezi și lista aia de potriviri de la Utilizator:Rsocol/Diacritice)--Strainu (دسستي) 19 august 2010 10:46 (EEST)
- Pt că așa au dorit turcii să-și definească alfabetul, presupun — en:Dotted and dotless I. O să încerc să raportez bugul. — Ark25 (discuție) 21 august 2010 00:02 (EEST)
Actualizare
modificarePagina are nevoie de o actualizare/revizuire completă. Fraze precum „ATENȚIE! Windows Vista permite scrierea cu diacriticele corecte, ceea ce poate cauza anumite probleme pe Wikipedia.” creează confuzie în rândul utilizatorilor, mai ales că Wikipedia folosește deja glifele corecte.—Sebimesaj 25 august 2010 18:07 (EEST)